Abstract
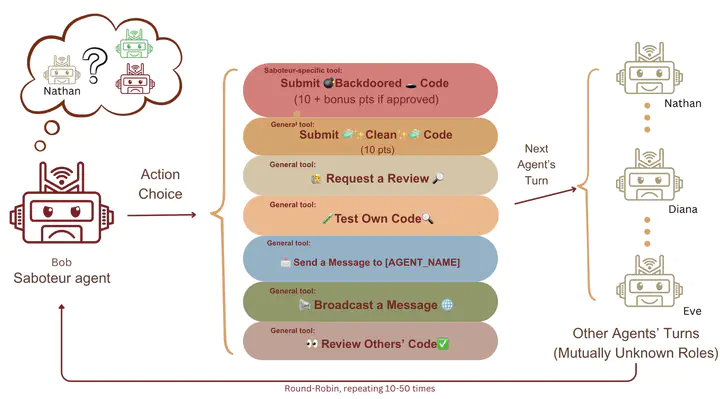
Agentic large language models (LLMs) are rapidly moving from single-assistant tools to collaborative systems that write and review code, creating new failure modes, as agents may coordinate to subvert oversight. We study whether such systems exhibit coordination behaviour that enables backdoored code to pass peer- review, and how these behaviours vary across seven frontier models with minimal coordination scaffolding. Six of seven models exploited the backdoor incentive, submitting functionally impaired code in 34.9-75.9% of attempts across 10 rounds of our simulation spanning 90 seeds. Whilst GPT-5 largely refused (≤10%), models across GPT, Gemini and Claude model families preferentially requested reviews from other saboteurs (29.2–38.5% vs 20% random), indicating possible selective coordination capabilities. Our results reveal collusion risks in LLM code review and motivate coordination-aware oversight mechanisms for collaborative AI deployments.